L’article ci-dessous a été refusé à la conférence The Ethics of Data Science: The Landscape for the Alan Turing Institute organisé par The Alan Turing Institute, nous avons toutefois souhaité le partager avec vous. Bonne lecture !
The Hitchhiker’s Guide to Ethics:
the Journey towards Raising Awareness in Natural Language Processing
Alain Couillault, Karën Fort, Gilles Adda, Maxime Amblard, Jean-Yves Antoine, Hugues de Mazancourt
Ethics, NLP and Everything
Natural Language Processing (NLP), like any other science, is confronted to ethical issues, both regarding the way science is conducted (plagiarism, reproducibility, transparency) and regarding the effects of its results on society. Some issues are specific to the very nature of NLP: the building, transformation or annotation of the (sometimes huge) language resources (corpora or dictionaries) NLP (sometimes heavily) relies on implies to set up and drive large scale projects which involve human resources. NLP techniques are also often used to analyze documents which, by their nature or their content, require thoughtful considerations regarding ethics. Just think of Email corpora (De Mazancourt et al., 2014), medical corpora (Grouin et al., 2015), schizophrenics’ speech corpora (Amblard et al., 2015) or suicide letters (Bretonnel Cohen et al., 2015). NLP is also called for when it comes to providing tools for ethics, for anonymizing documents or discovering plagiarism. This article describes the various actions we conducted to raise awareness for ethics within the NLP community.
Thanks for all the Answers
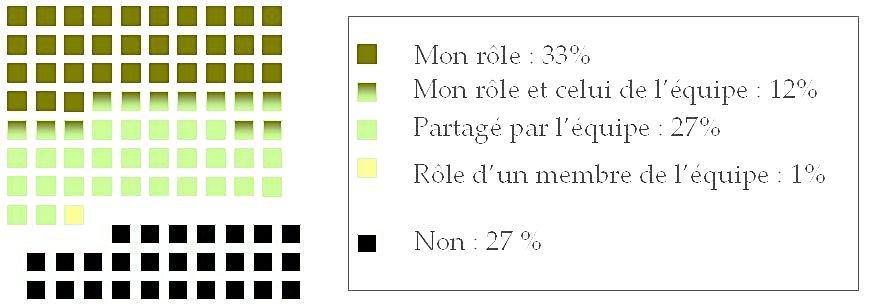
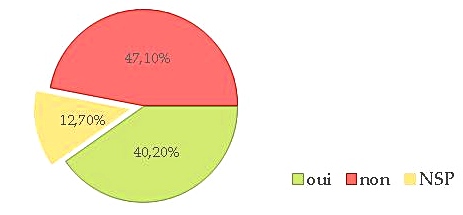
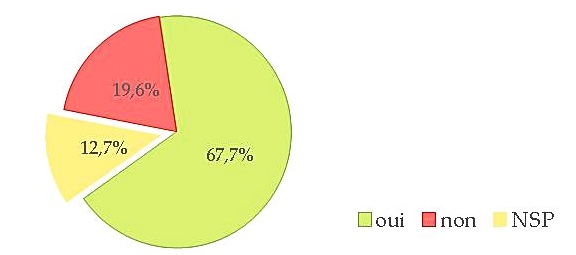
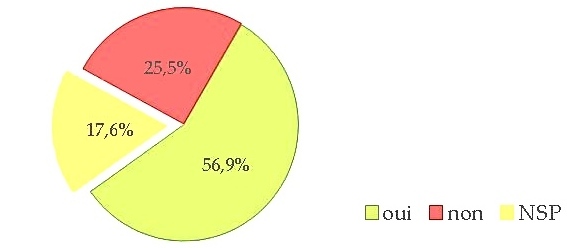
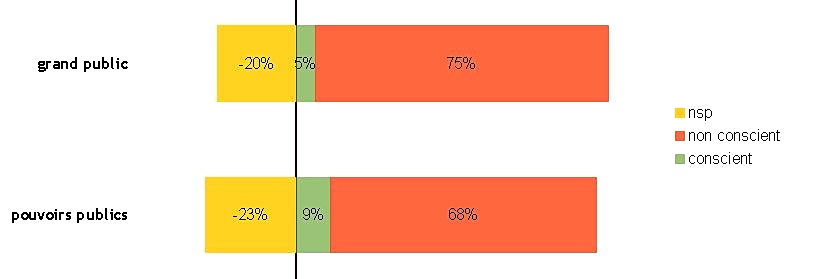
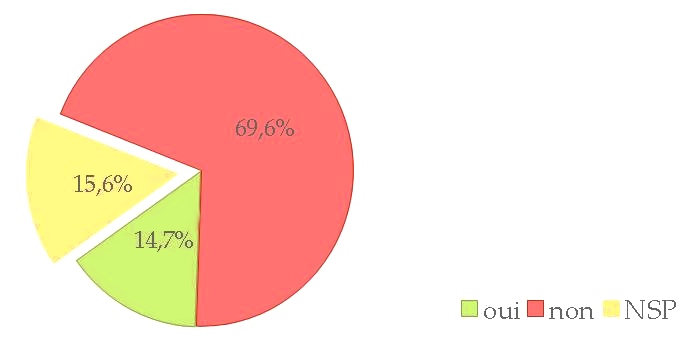
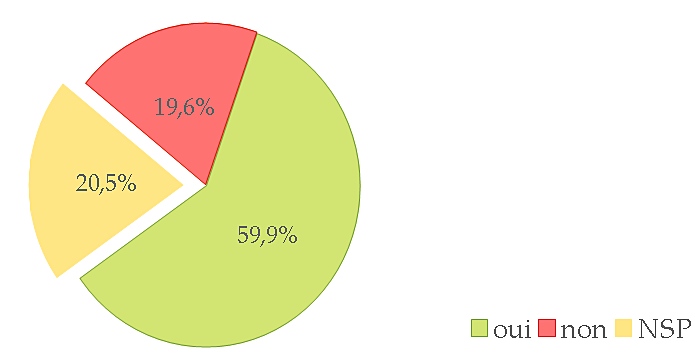
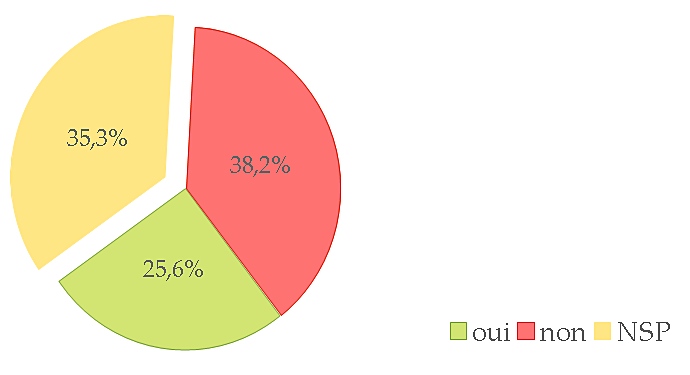
It all started with a position paper (Fort et al., 2011) on the growing use of the Amazon Mechanical Turk platform, stating that such platforms are not ethical with regards to the way Turkers (i.e. task workers) are paid, underpaid, or even not paid. We then broadened our standpoint and enlarged our group by involving private and public bodies in the writing of an Ethics and Big Data Charter (Couillault et al., 2014), which aim was to document as much as possible the building of language resources. The Ethics and Big Data Charter is a form split into three sections respectively dedicated to traceability, legal and licensing issues, and specific requirements (i.e. related to the very nature of the resource content). While the Charter has seldom been used for what it had been designed for (i.e. document language resources), we found out that talking and publishing about it and, hence, about ethics, rose interest, if not awareness, among researchers. It was then decided to push further and organize dedicated workshops in France, in November 2014 and June 2015. These workshops gave the opportunity to cover a large scope of the ethical issues pertaining to NLP, and were attended by a rather large audience. During one of the workshops, the idea arose to create a blog to share ethics-related standpoints and to address a larger audience. A poll was also conducted, partly to collect information on the NLP researchers’ viewpoint to NLP and, we must admit, rhetorically to raise awareness. More than 100 people answered the poll (which, with regards to the French speaking NLP community is a reasonably large number) and, among them, more than thirty people volunteered to get involved in ethics-related actions. We will present the main lessons drawn from this consultation, concerning various issues such as researchers ethical responsibility, data privacy and perpetuity, data producers payment etc.
And another Thing…
We have witnessed a motivating growing interest in the NLP community for ethics, and we are eager to take more actions to further raise awareness and create momentum.
The poll on Ethics and NLP has been translated into English and addressed to a large, international audience. It is under way and, as of September 2015, more than 260 people have participated. We plan to publish the results at an international conference and journal to enlarge even further the number of people interested. We have also worked on a second version of the Ethics and Big Data Charter to extend to other domains requiring data sets (such as medicine or European projects). The next TALN conference (organized by ATALA, the French association for NLP), will include a thread on ethics, and a special issue of the international TAL journal will be dedicated to ethics and NLP. Hopefully, all these efforts will help designing standards and solutions for ethics in NLP.
This paper, including section headers and footnotes, was 42 lines long in the original paper.
References
Amblard, M., Fort, K., Demily, C., Franck, N., and Musiol, M. (2015). Analyse lexicale outillée de la parole transcrite de patients schizophrènes. Traitement Automatique des Langues, 55(3):25, August.
Bretonnel Cohen, K., Pestian, J. P., and Fort, K. (2015). Annotating suicide notes : ethical issues at a glance. In ETeRNAL (Ethique et Traitement Automatique des Langues), Caen, France, June.
Couillault, A., Fort, K., Adda, G., and De Mazancourt, H. (2014). Evaluating Corpora Documentation with regards to the Ethics and Big Data Charter. In International Conference on Language Resources and Evaluation (LREC), Reykjavik, Iceland, May.
De Mazancourt, H., Couillault, A., and Recourcé, G. (2014). L’anonymisation, pierre d’achoppement pour le traitement automatique des courriels. In Journée d’Etude ATALA Ethique et TAL, Paris, France, November.
Fort, K., Adda, G., and Cohen, K. B. (2011). Amazon Mechanical Turk: Gold mine or coal mine? Computational Linguistics (editorial), 37(2):413–420.
Grouin, C., Griffon, N., and Névéol, A. (2015). Étude des risques de réidentification des patients a partir d’un corpus désidentifié de comptes-rendus cliniques en francais. In Proc. of the TALN workshop ETeRNAL, pages 12–24, Caen, France, June.