
En matière de recherche, s’il est un sujet où scientifiques et doxa populaire se rejoignent, c’est bien celui d’une élaboration continue de la connaissance par validation (ou réfutation) expérimentale des hypothèses. De nombreuses études en sociologie des sciences ont montré que cette vision objectiviste contenait une part de mythe (Latour &Woolgar 1979), fondé avant tout par les sciences dures expérimentales (Bensaude-Vincent 2013). Il n’en reste pas moins que la puissance opérative de cette vision de l’activité scientifique reste prédominante dans la pratique du chercheur, en sciences expérimentales du moins.
Situé à l’interface entre les sciences humaines et les sciences expérimentales, le TALN (Traitement Automatique des Langues Naturelles) est un domaine de recherche idéal pour observer l’influence de ce paradigme objectiviste. Pendant de nombreuses années (où, avouons-le, les applications opérationnelles étaient encore rares), l’évaluation de la production scientifique faisait la part belle au côté stimulant et originel des idées proposées. Le TALN semblait avant tout relever de la République des Idées chère aux sciences humaines. Depuis près de trois décennies, le TALN a désormais pris résolument le parti d’une évaluation supposée objective de ses travaux, en particulier sous la forme de campagnes d’évaluation compétitives (shared tasks).
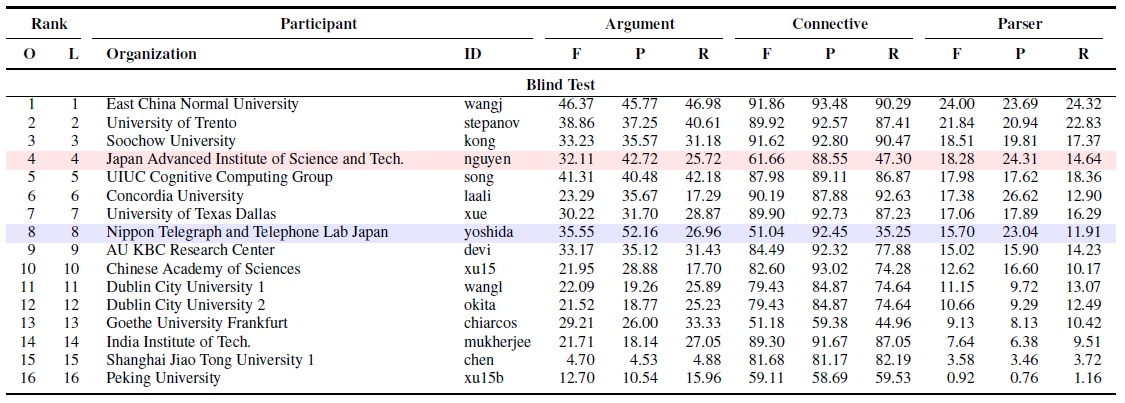
L’affaire se déroule ainsi : une tâche particulière est définie, un jeu de données commun est constitué pour permettre le développement des systèmes participant à la compétition, et, au bout d’une période fixée, ces derniers sont testés sur une base de test que l’on suppose être représentative de la tâche. On obtient alors un classement des systèmes participants. A titre d’exemple, la figure ci-dessous résume les résultats de la dernière campagne d’évaluation sur l’identification de relations de discours (Shallow Discourse Parsing shared task) de la conférence CoNLL’2015 (Xue et al. 2015) . Nous n’allons pas expliquer ici en détail ces résultats. Disons simplement, que pour trois sous-tâches données (Argument, Connective, Parser), les participants sont classés (O = official) suivant une métrique (F = F-mesure, qui combine deux mesures de Précision P et de Rappel R) calculée une fois pour toute sur le corpus de test. Le classement final résultant d’une combinaison entre les scores obtenus sur les trois sous-tâches.
 Ces campagnes compétitives ont toujours un fort impact au sein de la communauté scientifique. Aussi, lorsque notre laboratoire LI a remporté la campagne ETAPE d’évaluation des systèmes de détection automatique des entités nommées sur le français parlé (Nouvel 2013), nous ne nous sommes pas privés de mettre en exergue ce résultat.
Ces campagnes compétitives ont toujours un fort impact au sein de la communauté scientifique. Aussi, lorsque notre laboratoire LI a remporté la campagne ETAPE d’évaluation des systèmes de détection automatique des entités nommées sur le français parlé (Nouvel 2013), nous ne nous sommes pas privés de mettre en exergue ce résultat.
Pourtant, pourtant… que représentent vraiment ces classements ? Récemment, j’ai invité une amie qui venait de terminer une thèse en modélisation cognitive computationnelle, et qui à ce titre a l’habitude des travaux en psychologie expérimentale, à assister à un atelier en TALN. Sa réaction face à nos présentations fut immédiate : « vous ne comparez que des résultats bruts, ne calculez-vous jamais la pertinence statistique de vos observations pour fonder votre analyse critique ? ». Gêne de ma part, car que répondre à cet évident manque de rigueur de nos procédures d’évaluation ? Eh oui, l’East China Normal University a peut-être remporté la sous-tâche Argument de la shared task de CoNNL avec une F-mesure de 46,37, mais aucune étude ne nous montre que ce résultat est statistiquement supérieur au 41,31 de l’UIUC ! Pour pouvoir répondre à cette question, il aura fallu diviser la base de test en sous-corpus, regarder la variabilité des résultats obtenus et procéder à des tests de significativité statistique (test paramétrique de Student, test U de Wilconxon-Mann-Withney, par exemple) pour pouvoir vraiment décerner une première place incontestable. Ces tests, que l’on rencontre très rarement dans nos campagnes d’évaluation, sont pourtant enseignés dès la licence à des étudiants en en statistique et analyse de données !

Les classements de nos campagnes d’évaluation ont ainsi autant de valeur qu’une épreuve de saut à la perche aux Jeux Olympiques où le meilleur athlète de la discipline peut se retrouver dans un mauvais jour. Dans le cas présent, l’UIUC a peut-être eu simplement la malchance d’être confrontée à un jeu de données qui lui convenait moins bien…
Les chercheurs en TALN acceptent cet état de fait car ils s’en remettent à un autre mythe de la discipline : celui du corpus représentatif. Ce mythe, si cela en est un, est lourd de conséquences, car les techniques d’apprentissage automatique que nous utilisons majoritairement n’ont qu’un but : non pas de résoudre un problème qui pourrait donner lieu à des applications réelles, mais de s’adapter au mieux à un jeu de données extrait du problème. On imagine aisément les travers d’un tel choix de paradigme si la représentativité de nos corpus n’était pas au rendez-vous.
Or, cette représentativité n’a rien de garantie. J’en veux pour preuve les résultats d’un stage de Master que j’ai encadré récemment. Je vous explique. Lucie Dupin, la stagiaire, avait pour tâche de développer un système de détection automatique des noms d’auteurs dans des blogs, ceci sur des données fournies par l’entreprise (Elokenz – Cicero Labs) qui finançait le stage. Sans être très difficile, cette tâche est plus complexe qu’on peut l’imaginer à prime abord si on veut atteindre une généricité de traitement. Chaque blog a en effet une manière qui lui est propre de présenter l’auteur d’un post, et comme plusieurs noms propres peuvent figurer sur une page de blog, détecter la bonne entité nommée n’est pas trivial. Pour s’assurer de la représentativité des données, Elokenz a opéré une extraction sur une très grande diversité de blogs. Nous avons entraîné un classifieur SVM sur ces données d’apprentissage, en réservant classiquement un dixième du corpus pour le test du système (et en procédant à une technique dite de validation croisée qui nous assure que le système n’apprend pas par coeur mais tente de généraliser à partir de ses données d’entrainement). Les résultats furent très satisfaisants, avec un taux de bonne détection (Accuracy) de 91 % (Dupin et al., 2016). Lucie ayant bien avancé durant son stage, il nous restait une semaine à occuper avant sa soutenance. Elokenz nous a alors fourni un nouveau corpus de test, tout aussi varié que le précédent, mais extrait d’autres blogs. Patatras, l’évaluation (sans nouvel entraînement) du système nous a donné une robustesse déclinant à 66 % ! Certains choix faits au cours du stage ont confirmé leur intérêt sur cette seconde évaluation : le travail de Lucie n’était donc heureusement pas remis en cause. Mais il était clair que nous avions développé un système sur un corpus jugé représentatif de tous, et qui ne l’était pas. Au final, nous n’avions fait qu’adapter notre classifieur aux données, sans avoir l’assurance que sa robustesse sur tout type blog serait suffisante dans un cadre industriel.
Je pose donc la question : quand nous sommes nous interrogés sur la pertinence des corpus sur lesquels nous développons nos systèmes ? Et qui parmi nous ne passe pas des semaines à adapter (tuning) son système pour qu’il colle au mieux aux données d’apprentissage, afin d’obtenir un bon classement, plutôt que de réfléchir au développement d’approches originales ?
Vous savez quoi, je commence à douter de notre première place lors de la campagne Etape. Bon, à dire vrai, j’en doutais depuis longtemps…
Jean-Yves Antoine
Repères bibliographiques
- Bernadette Bensaude-Vincent (2013) L’opinion publique et la science : à chacun son ignorance, La Découverte, Paris.
- Lucie Dupin, Nicolas Labroche, Jean-Yves Antoine, Jean-Christophe Lavocat, Agata Savary (2016) Author name extraction in blog web pages: a machine learning approach. Actes JADT’2016. Nice, France
- Bruno Latour et Steve Woolgar (1979) Laboratory life : the social construction of scientific facts. Sage, London. Trad. Fr. La vie scientifique : la production des faits scientifiques, La Découverte, Paris, 1988.
- Nianwen Xue, Hwee Tou Ng, Sameer Pradhan, Rashmi Prasad, Christopher Bryant, Attapol T. Rutherfort (2015). The CoNLL-2015 Shared Task on Shallow Discourse Parsing. Proc. CoNLL’2015, Pekin.
Très intéressant message. Pas mal de points que j’ai déjà évoqués avec quelques collègues depuis que je m’intéresse plus particulièrement aux évaluations de la désambiguïsation lexicale (WSD) et à celles sur la traduction automatique. Ce sont des éléments que l’on ne lit jamais et qui sont pourtant essentiels.
Pour moi, dans une campagne, on est vraiment et uniquement au niveau de la compétition. C’est une course d’un jour avec la difficulté supplémentaire que l’on découvre tout ou partie du terrain pendant l’épreuve. Effectivement, aucun test de significativité n’est réalisé pour comparer les différents systèmes. Je pense que les organisateurs ne peuvent pas mettre ça en place. Ça reste une compétition et le gagnant est celui qui obtient le meilleur résultat final. Ça n’empêche pas d’analyser les résultats pour essayer de savoir si un système a été meilleur sur telle partie du corpus ou tel phénomène. Les organisateurs le font parfois mais c’est une tâche quasi infinie.
J’aurais tendance à penser que de plus en plus de personnes ont perçu le problème. J’en veux pour preuve le nombre de relecteurs qui demandent aujourd’hui l’évaluation d’un système présenté dans un article sur un plus grand nombre de corpus. Évidement, 1) ça ne fait que réduire la marge d’erreur 2) tous les systèmes n’ont pas participé à toutes les évaluations.
Pour le problème de Lucie, n’aurait-il pas mieux fallu faire une validation croisée par rotation ? Je coupe mon corpus en n parties, j’apprends sur n-1 parties et je teste sur la nième. Je fais la même chose sur chacune de mes n parties et je peux faire des test de significativité qui me permettent de mieux analyser la méthode.
Comme Didier, je crois effectivement que les chercheurs sont désormais conscients du problème, comme le montrent les discussions off des campagnes d’évaluation (détection des entités nommées) auxquelles j’ai participé. Par contre, cela est bien moins sûr de nos étudiants, et encore moins du grand public auquel nous vendons parfois des résultats ronflants. Ne pourrait-on pas être plus prudents ? Par ailleurs, je pense qu’il doit être possible bien souvent d’associer des tests de significativité dans ces campagnes. Bon, Didier travaille en traduction automatique où déjà, les résultats peuvent changer du tout au tout suivant la métrique d’évaluation choisie, si j’ai bien suivi la chose, donc là, j’imagine la galère.
Concernant le travail de Lucie, en fait, nous avions bien fait un apprentissage avec validation croisée comme le suggère Didier, pour éviter un apprentissage « par coeur ». D’où notre grand étonnement, qui nous a vraiment posé la question « qu’est-ce qu’un corpus représentatif » ? Merci pour la remarque, je vais rajouter une petite note sur le sujet dans mon texte, pour clarifier auprès des experts…