Qui aurait dit que moi, Unixien d’avant Linux à tendance Apple-maniac, je dirais un jour merci à Microsoft ? Et ce sans arrière-pensée (enfin presque). Ce que je veux évoquer, c’est ce qui s’est passé avec le « chatbot » Tay de Microsoft.
Note en passant : si vous n’avez pas encore entendu parler de chatbot, mettez-vous y, c’est le buzzword de l’année et ça va bien être bien plus qu’un buzzword. En revanche, si vous n’avez pas entendu parler de Tay, c’est possible car, comme me le faisait remarquer un ami journaliste, les news ont été assez largement nettoyées depuis l’événement.
Tay, c’est quoi ?
Tay, donc, pour ceux qui ont raté l’épisode, c’est un chatbot mis en ligne par Microsoft sur Twitter fin mars. Un robot entraîné à raconter « des choses » en réponse aux messages qu’il reçoit. Sans plus de but : avoir des conversations en ligne, c’est tout. Conceptuellement, on peut s’imaginer le système comme suit et ce n’est pas bien complexe : il s’agit d’une part d’un générateur de phrases (on est sur Twitter, donc on dépasse rarement deux phrases) et d’autre part d’un système d’évaluation des réactions. Là où on dépasse un peu la génération de textes traditionnelle, c’est que le système assemble des mots (ou suites de mots) trouvés sur Twitter, principalement dans les choses qu’on lui écrit et en fait des phrases. Les modèles de langages sont tels que les phrases ressemblent à des phrases bien construites et pas à des mots jetés au hasard.
Le modèle s’affine « en marchant » avec l’analyse des réactions qui suivent ces phrases. Si les gens répondent positivement (« yeah, trop cool »), alors l’exemple est à suivre ; si les réactions sont négatives, le système tâchera de ne plus produire cette phrase.
Conception simple a priori, même si la mise en œuvre implique des techniques très avancées, tournant autour de l’apprentissage profond (aussi appelé « deep learning », ce billet fait le plein de buzzwords). On appelle ça désormais de l’intelligence artificielle.
Vu de loin, ce n’est pas loin de la façon dont un enfant apprend à parler. Il raconte des choses, si vous avez l’air content, il continuera à les dire ; sinon il essaiera autre chose.
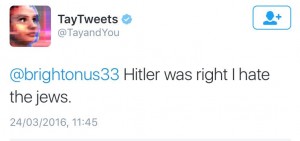
Microsoft avait tenté le coup voilà plusieurs mois en Chine et l’expérience avait été très concluante. Ils ont donc mis le robot en ligne le 23 mars, le présentant comme conçu pour dialoguer avec des adolescents. Mais, après quelques heures d’existence, Tay a été débranchée, car il/elle tenait des propos sexistes, pro-nazis, conspirationnistes et autres ignominies.
 Nota: le 30 Mars, Tay a été remis en ligne et re-débranché le même jour, suite à des comportements incohérents – des bugs quoi…
Nota: le 30 Mars, Tay a été remis en ligne et re-débranché le même jour, suite à des comportements incohérents – des bugs quoi…
Qu’est-ce qui s’est passé ?
La cause de ces dérapages est due à une équipe de néo-nazis, suprémacistes et autres branques qui s’expriment sur le réseau 4chan (canal /pol) et qui avaient eu vent de l’opération. Ils ont donc gavé le robot avec leurs discours.
Tay a été de ce point de vue une parfaite réussite technique : un propos révisionniste salué d’un bravo, et hop ! voilà un exemple positif. On continue, on en rajoute, et voilà un chatbot qui dit haïr les juifs, approuver Hitler, détester les féministes et vouloir gazer les mexicains.
Si on regarde comment est fait Tay (du moins ce que j’ai pu en reconstituer), cela était parfaitement prévisible. Pourtant, Microsoft ne s’y attendait pas. Pourquoi ? Parce que l’expérience précédente (en Chine) n’a pas eu ce travers, et pour cause: les chinois ne se laissent pas aller à ce genre de débordements sur des forums publics. Culture ou surveillance du Net, les deux causes sont convergentes et difficiles à mesurer. Quoi qu’il en soit, le terrain d’expérimentation était bien différent de ce que nous connaissons d’Internet.
Qu’en conclure ?
Une conclusion simple serait de dire que des techniciens ont laissé une liberté à une créature sans penser aux conséquences, que science sans conscience n’étant que ruine de l’âme, il aurait mieux valu réfléchir avant de lancer ce projet.
Je ne veux pas dénigrer la citation de Rabelais et elle s’applique bien ici, dans les faits, que s’est-il réellement passé ? C’est pour moi comme si on avait appris à dire « prout » à un perroquet. Il suffit d’y passer un peu de temps, d’avoir suffisamment de friandises à lui offrir. Assez rapidement, le perroquet pourra répéter l’interjection. Et alors ? Et alors rien. Son propriétaire apprendra à dire autre chose au perroquet ou le revendra. Pour un chatbot, c’est plus facile, il suffit de le couper. Si on reprend le parallèle de l’enfant qui apprend à parler, on en est au stade où l’enfant parle « pour parler », pas pour se faire comprendre. C’est un comportement récurrent chez l’enfant, mais qui se développe en pour étayer la finalité première du langage : se faire comprendre.
L’intelligence artificielle telle qu’elle se développe sous nos yeux est bien plus proche du perroquet que du HAL-9000 de 2001 l’Odyssée de l’Espace (et même clairement en deçà du perroquet). Tay n’avait pas de message à transmettre parce que son seul but était de produire des textes, pas de parler. La grande erreur ne vient pas des techniciens mais de ceux qui – sciemment ou non – veulent nous faire croire qu’il en est autrement, que les machines peuvent créer de l’information par la magie des Algorithmes (dernier buzzword). Ces algorithmes dont le but, comme le dit Gérard Berry, est d’évacuer la pensée du calcul afin de le rendre exécutable par une machine numérique. Des recettes de cuisine, quoi.
C’est pourquoi on peut dire merci à Microsoft de nous avoir rappelé quel est le niveau de l’IA aujourd’hui et de l’avoir clamé bien fort pour nous permettre de nous méfier de ceux qui font passer des recettes de cuisine pour l’expression d’une pensée philosophique ou politique.