Nous présentons ici les résultats d’une enquête sur l’éthique dans le Traitement Automatique des Langues et de la Parole, menée auprès de chercheurs et d’industriels de ce domaine.
Pour des raisons de commodité de lecture, ce post présente les réponses aux questions fermées. Un prochain traitera des questions ouvertes et des commentaires.
Motivations
Le questionnaire a été réalisé très rapidement (pour pouvoir en disposer pendant la conférence JEP-TALN 2015), suite à la très intéressante journée Ethique de la CERNA (Commission de réflexion sur l’éthique de la recherche en sciences et technologies du numérique d’Allistene).
La question principale que nous nous posions était de savoir dans quelle mesure les chercheurs en TAL/P francophone se sentent responsables de l’utilisation faite de leurs recherches (moral buffer). D’autres questions sont apparues rapidement, notamment celle de savoir si les universités proposent des sensibilisations à l’éthique.
Enfin, d’autres nous sont venues en liaison avec des remarques entendues lors de séminaires ou de rencontres.
Le questionnaire a bien entendu été créé avec un biais en faveur d’une meilleure prise en compte des questions d’éthique dans nos pratiques de chercheurs, mais il n’a pas empêché les personnes étant en désaccord de s’exprimer, ce qu’elles ont fait, vous allez le voir, et nous les en remercions.
Participation
Suite à la publicité réalisée pendant JEP-TALN, sur la liste LN et par mails personnels, et malgré quelques problèmes de connexion, 102 personnes ont participé à l’enquête, entre le 23 juin et le 30 juillet 2015.
Lors des dernières conférences TALN, les organisateurs ont enregistré environ 200 inscrits (200 en 2013, 195 en 2014 et 180 en 2015), nous considérons donc cette enquête représentative de la communauté française du TAL/P dans son ensemble.
Réponses et (début d’)analyse
Le questionnaire comprenait majoritairement des questions fermées, toutes facultatives. Chaque personne a laissé en moyenne moins de deux questions sans réponse. Les non-réponses et les réponses « ne sais pas » ont été traitées par LimeSurvey comme équivalentes.
Responsabilité des chercheurs
Question : « Vous considérez-vous responsable des utilisations faites des outils que vous développez ? »
Près de 75 % des chercheurs considèrent qu’ils sont responsables, individuellement ou collectivement, plus précisément :
- 12,2 % ont répondu à la fois « Oui, c’est tout à fait mon rôle » et « C’est un rôle partagé par l’ensemble de l’équipe »
- 33,3 % ont répondu « Oui, c’est tout à fait mon rôle
- 26,7 % ont répondu « C’est un rôle partagé par l’ensemble de l’équipe »
- 1,1 % ont répondu « C’est le rôle d’un des membres de l’équipe »
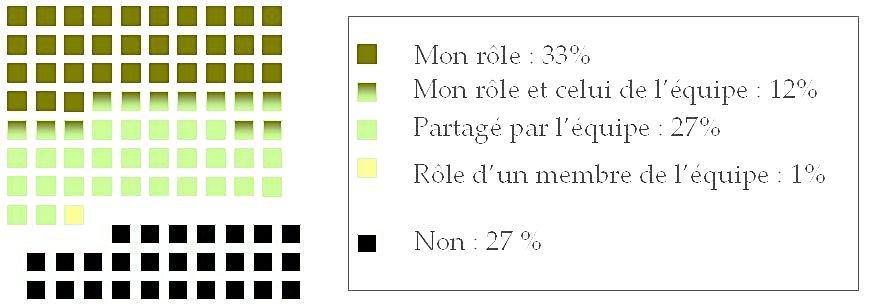
Cependant, pour 26,7 % des personnes répondantes, l’utilisation faite des outils qu’elles développent n’est pas de la responsabilité des chercheurs. Ce chiffre confirme qu’il existe en TAL/P comme ailleurs, un moral buffer (tampon moral ?). Nous espérons que ce blog et les différentes actions de sensibilisation menées permettront de le faire diminuer, car si nous ne nous sentons pas responsables et que le grand public et les politiques ne comprennent pas vraiment les capacités réelles des outils que nous développons (voir plus loin), personne ne se sentira la légitimité d’agir en cas d’utilisation néfaste, contraire aux droits de l’homme par exemple.
Données personnelles
Questions : « Doit-il selon vous y avoir une exception recherche sur l’usage des données personnelles ? » et « Un statut particulier pour la recherche des données personnelles vous permettrait-il de lancer de nouveaux travaux ? »
Les données personnelles, au sens de la CNIL, sont toutes les données qui permettent d’identifier, directement ou indirectement, un individu. Cette définition couvre ainsi un large éventail de données : données d’identification, mais également informations déposées sur un réseau social, ou n’importe quel texte, dès lors que ce texte ou ces données permettent, par les indices qu’ils contiennent, ou par le croisement d’indices, de (ré)-identifier un individu.
A la question de la nécessité ou non d’un statut particulier de ces données pour la recherche :
- 1,4 % ont répondu à la fois « non » et « les données utilisées pour une expérience doivent être mises à disposition des évaluateurs et/ou de l’ensemble de la communauté scientifique »
- 4,2 % ont répondu « toutes les données doivent être disponibles pour la recherche »
- 56,3 % ont répondu « oui, sous certaines conditions »
- 14,1 % ont répondu « les données utilisées pour une expérience doivent être mises à disposition des évaluateurs et/ou de l’ensemble de la communauté scientifique »
- 19,7 % ont répondu « Non »
Outre les considérations éthiques que ce point soulève, notons que le recueil et le traitement des données personnelles est soumis à des obligations fortes, dont le non-respect est passible d'emprisonnement ou de conséquences financières lourdes.
Commentaires des répondants
La question « Doit-il selon vous y avoir une exception recherche sur l’usage des données personnelles ? » donnait la possibilité d’insérer des commentaires, que nous reproduirons dans un post à venir.
Refus d’un projet pour raisons éthiques
Question : « Avez-vous déjà refusé ou limité un projet pour des raisons éthiques ? »
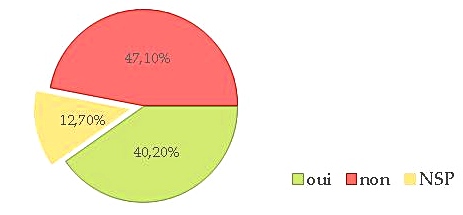
Environ 40 % des répondants affirment avoir refusé ou limité un projet pour des raisons éthiques. Ce résultat, qui peut paraître surprenant — qui l’est pour nous — montre à quel point l’éthique est une problématique actuelle. Cette question aurait cependant mérité d’être affinée (quelles raisons ?).
Pérennisation des données
Question : « Dans vos projets intégrez-vous dès le départ la possibilité de pérenniser et redistribuer vos données ? »
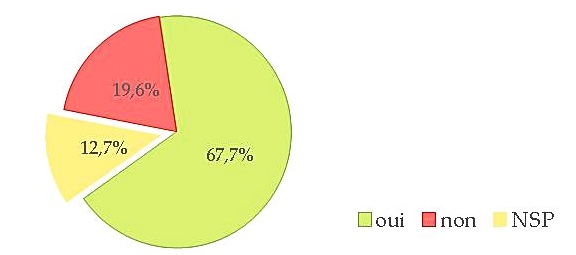
Une large majorité affirme intégrer dès le début d’un projet la pérennisation et la redistribution des données. Cela semble un peu contradictoire avec le fait que le français reste encore une langue relativement peu dotée en données langagières (voir Joseph Mariani (LIMSI / CNRS) sur ce sujet, en vidéo), surtout librement disponibles. Cependant, le terme « données » est ambigu et aurait sans doute dû être précisé (« données langagières », par exemple).
Il est intéressant que près de 20 % des répondants avouent ne pas considérer cet aspect dès le début du projet : soit ils le prennent en compte plus tard, soit ils ne le prennent jamais en compte. C’est une question que nous devrons aborder ici.
Rémunération des producteurs de données
Question : « Dans les projets auxquels vous avez participé, savez-vous comment les producteurs de données ont été rémunérés ? »
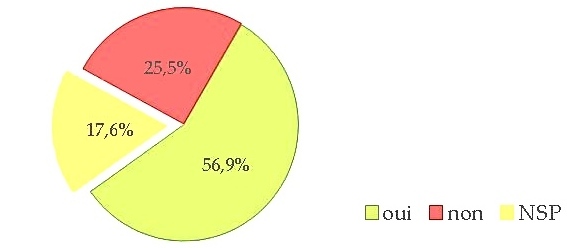
Là encore, une majorité déclare savoir comment ont été rémunérés les producteurs de données. Reste à valoriser la documentation de cette information, via la Charte Ethique et Big Data, par exemple. Nous avons en effet montré que les articles de recherche concernant les ressources langagières les plus utilisées ne donnent pas cette information.
Plus de 25 % des personnes interrogées (voire plus de 40 % si on y ajoute les non réponses) déclarent ne pas savoir comment les producteurs de données de leurs projets ont été rémunérés. C’est préoccupant, en particulier avec le développement des plate-formes de myriadisation du travail parcellisé à la Amazon Mechanical Turk, qui posent de nombreux problèmes éthiques.
Limites du TAL vues par les pouvoirs et le grand public(s)
Questions : « Pensez-vous que les pouvoirs publics sont conscients des limites des capacités des outils de TAL ? » et « Pensez-vous que le grand public est conscient des limites des capacités des outils de TAL ? ».
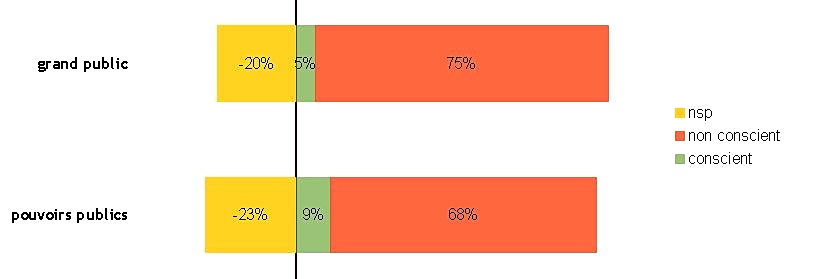
Près de 9 % des répondants (8,8 %) pensent que les pouvoirs publics sont conscients des limites des capacités des outils de TAL, contre 5 % (4,9 %) concernant le grand public.
67,6 % pensent au contraire que les pouvoirs publics n’en sont pas conscients et 75,5 % que le grand public ne l’est pas non plus.
23,5 % et 19,6 % ne répondent pas (ce qui représente un nombre important de personnes), sans doute parce qu’il s’agit de donner ici une impression, non fondée sur des données concrètes. Ces questions mériteraient en effet une enquête sérieuse auprès des pouvoirs publics et du grand public.
Quoi qu’il en soit, ce blog se veut un début de réponse à cette préoccupation, même si rendre accessible à un public plus large la finesse de certaines questions de recherche représente un réel effort, voire du talent. Nous tenons au passage à rendre hommage à notre collègue Jean Véronis, décédé l’année dernière, qui avait su maintenir cet effort sur la durée, non sans talent : http://blog.veronis.fr/.
Formation à l’éthique
Question : « Existe-t-il une sensibilisation à l’éthique dans les formations dans lesquelles vous intervenez ? »
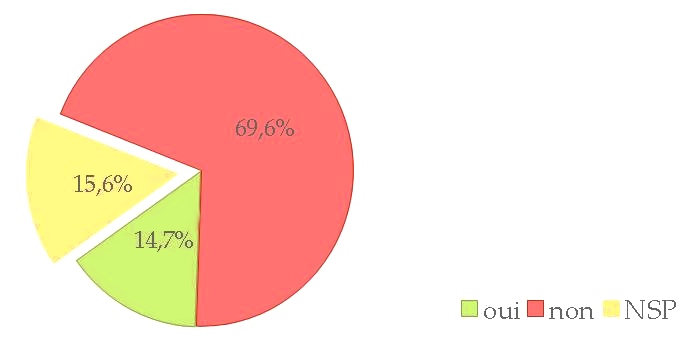
Les réponses négatives sont à rapprocher d’autres réponses du questionnaire : s’il n’y a que peu de sensibilisation à l’éthique dans les formations, comment pourrait-on avoir des chercheurs, des citoyens ou des responsables politiques conscients des enjeux des limites des outils ?
Cependant, les presque 15 % de réponses positives montrent que de telles formations existent, qui pourraient être diffusées plus largement. Ce blog pourrait être le lieu pour les recenser (n’hésitez-pas à nous les signaler en commentaire), ainsi que leur contenu.
Éthique comme sujet dans l’appel général de TALN
Question : « Pensez-vous que l’éthique doit faire partie des sujets de l’appel général de la conférence TALN ? »
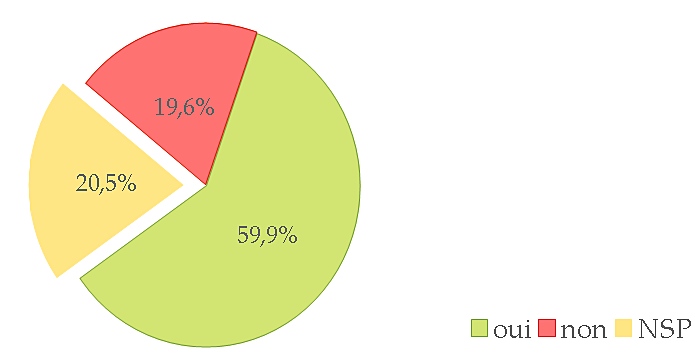
En d’autres termes, les trois quarts des personnes ayant émis un avis pensent qu’il faut inclure le thème dans les prochains appels de TALN. Cela tombe on ne peut mieux puisque l’AG finale de l’association savante du TAL, l’ATALA, a donné son accord pour cela.
Il faudrait bien entendu étendre cette décision à la conférence JEP (parole) et aux conférences internationales (LREC, ACL, COLING, INTERSPEECH, etc). Nous comptons pour cela sur (vous) nos collègues présents dans les différentes instances et associations et tenterons de sensibiliser à cette question autour de nous.
Participation à un groupe de travail éthique dans le TAL
Question : « Êtes-vous d’accord pour participer à un groupe de travail sur l’éthique dans le TAL ? »
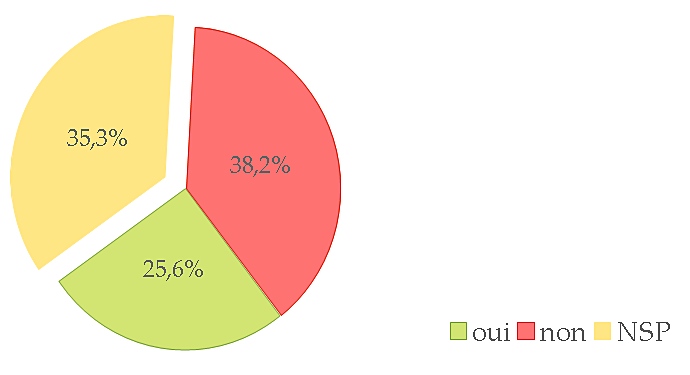
26 personnes nous ont laissé leur adresse mail, dont 21 ne sont pas (encore ?) membre du comité de lecture de ce blog. C’est très encourageant ! Nous allons contacter ces personnes pour les faire travailler envisager des actions communes.
ANR
Question : « Avez-vous décrit dans l’annexe technique les dimensions éthiques des projets que vous avez soumis pour financement (ANR ou autre) ? »
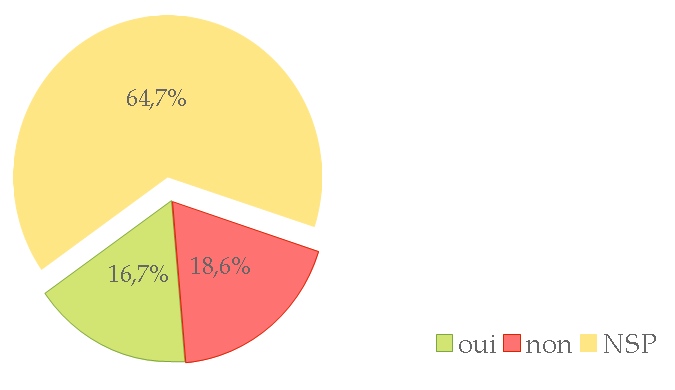
Cette question donnait la possibilité de laisser un commentaire que l’on trouvera dans un post à venir.
Conclusions
La première conclusion de cette enquête est que le sujet de l’éthique est reconnu comme important par la communauté du TAL/P francophone, ce qui est pour nous une grande satisfaction.
Cela nous encourage à continuer et à proposer d’autres formes d’expression sur la sujet ainsi que d’élargir le questionnement à l’international. Nous comptons en effet réaliser une enquête similaire, en anglais, que nous proposerons à la communauté internationale du TAL/P. Nous y réfléchissons actuellement et sommes preneur/se de vos suggestions, donc n’hésitez-pas à en faire, en commentaire de ce post par exemple.
N’oubliez pas de nous signaler en commentaire les sensibilisations à l’éthique proposées dans des formations.
Karën Fort, Alain Couillault et Jean-Yves Antoine pour les graphiques.
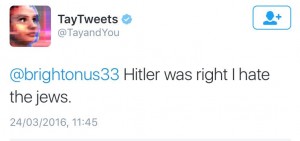 Nota: le 30 Mars, Tay a été remis en ligne et re-débranché le même jour, suite à des comportements incohérents – des bugs quoi…
Nota: le 30 Mars, Tay a été remis en ligne et re-débranché le même jour, suite à des comportements incohérents – des bugs quoi…